
「過去案件の図面、誰がどこに置いたかわからない」「20年前の仕様書を改訂したいけど、どこから手をつければいいのか」——中小製造業の現場を回っていると、必ずと言っていいほどこの悩みにぶつかります。
こんにちは、株式会社K.Platinum代表の沼田です。

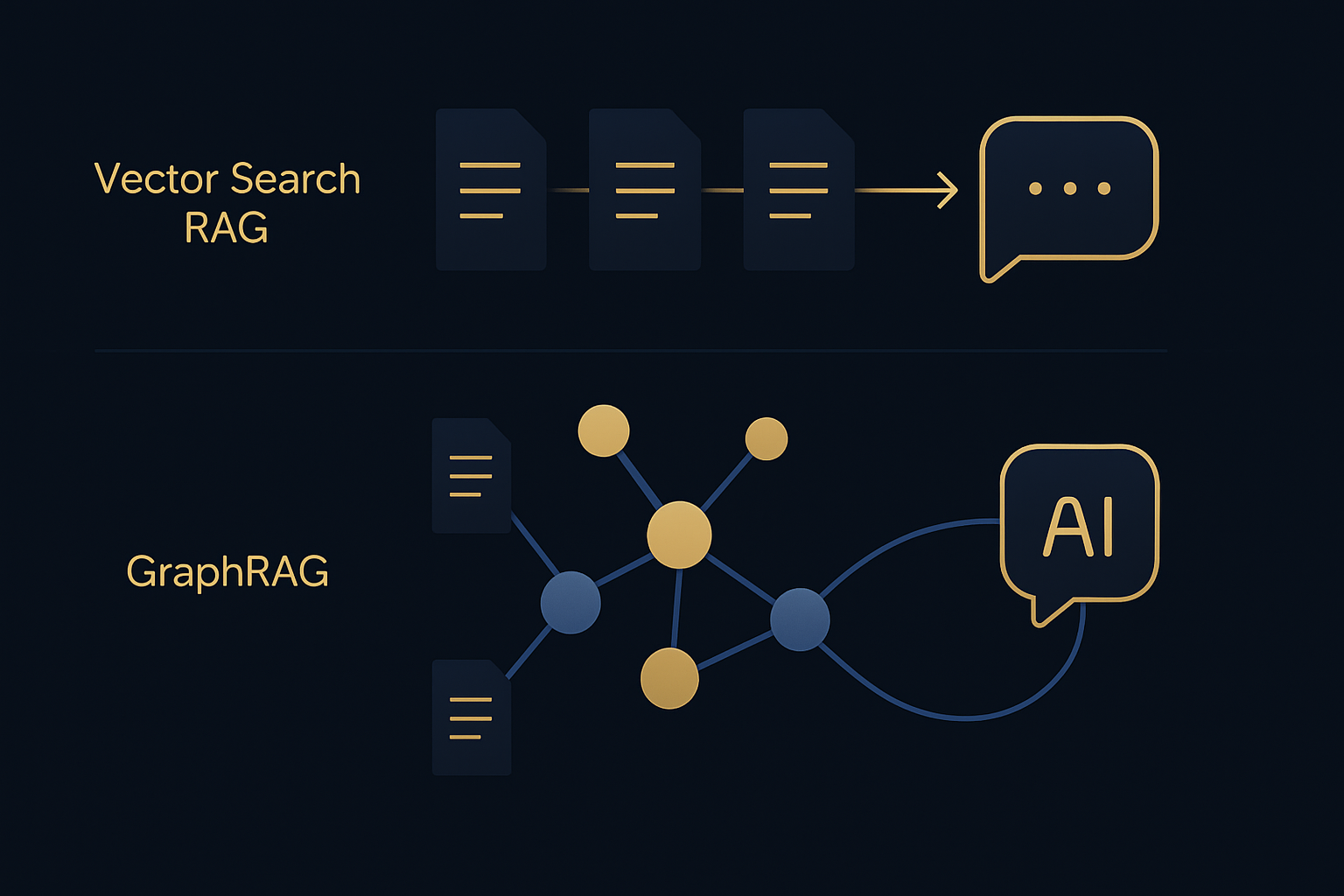
僕らはこの半年、ある中小製造業のお客さんと一緒にRAG(Retrieval-Augmented Generation)の導入をやってきました。最初の3ヶ月は普通のRAG(ベクトル検索 + LLM)で挑んで、見事に詰みました。そこからGraphRAGに切り替えて、ようやく「型番→部品→図面→改訂履歴→仕様書」をつなげて引ける検索ができるようになった——というのが今回の話です。
技術ブログっぽい体裁ですが、本質的に言いたいのは「中小製造業のRAGは設計が9割、実装が1割」というシンプルな話です。同じように図面・仕様書の検索で消耗している会社は多いはずなので、つまずいた所も含めて正直に共有します。
ベクトル検索だけのRAGが、製造業で詰む話
最初に正直に書いておきます。僕らは最初、王道のRAGで行けると思っていました。PDFをChunkに割って埋め込み、Pineconeに突っ込み、LLMで質問応答する——SaaSのドキュメント検索でうまくいくあのパターンです。
で、3週間でリリース直前まで行きました。デモも一見動きました。
でも、お客さんの社員さんに触ってもらった瞬間に詰まりました。「『SK-3850の旧版ボルトの図面を出して』って聞いても、SK-3850は出てくるんだけど、"旧版"が出てこない」「『この図面を改訂した時の根拠仕様書を見せて』が無理」。
そのとき僕は、自分が製造業のドキュメント構造を全然なめてたな、と思いました。
なぜ"図面と仕様書"は普通のRAGで検索できないのか — 3つの構造的理由
普通のRAGで詰まったのは、僕らの実装力の問題ではなく、製造業の資料の構造的特性のせいでした。整理すると3つあります。
1つ目: 「関係性」が情報の本体だから
製造業の図面・仕様書は、単体で意味を持つことが少ないです。「型番A」は「部品B-1, B-2, B-3」からなり、「部品B-1」は「サプライヤーX」が納入していて、「サプライヤーX」は「2019年に仕様変更通知Yを発行している」——このチェーン全体が知りたいことの本体です。
ベクトル検索は「意味的に似たChunk」を出すのは得意ですが、「Aから3ホップ離れたDを引いてくる」のは原理的に苦手です。
2つ目: 改訂履歴・派生がエグい
製造業の図面には改訂が付きものです。Rev.A, Rev.B, Rev.C……。「最新版を出して」「旧版を出して」「2018年時点で使われていたバージョンを出して」という時系列クエリが、現場では普通に飛んできます。
これも、Chunkを埋め込むだけのRAGには重い。なぜなら「最新」「旧版」は文章にほぼ書かれていないからです。メタデータとして外に出して、グラフのエッジとして扱わないと、原理的に解けません。
3つ目: そもそも図面のChunkが意味を持たない
これが一番痛かった。
仕様書PDFは、Chunkに割って埋め込めばまだ何とかなります。日本語の連続テキストだから。
でも、CAD出力の図面PDFはダメです。中身は「数字、線、寸法、矢印、注記、表題欄」が組み合わさったほぼ画像で、テキストレイヤーは型番・寸法・注記・表題欄くらいしか入っていない。これを200文字でChunkして埋め込んでも、検索しようがない。
つまり、図面PDFに対しては「OCR + 構造抽出 + メタデータ化」を先にやって、それを「グラフのノード」として持たないと、そもそも検索の土俵に乗らないわけです。
GraphRAGとは何か — ナレッジグラフ × ベクトル検索の二段構え
ここで出てきたのがGraphRAGです。Microsoft Researchが2024年に出した論文以降、急速に注目されている方式で、ざっくり言うとこうです。
GraphRAG = Knowledge Graph + ベクトル検索 + LLM の3層構成
普通のRAGが「ベクトルDB ↔ LLM」の二層なのに対して、GraphRAGは間にナレッジグラフを挟みます。
- ナレッジグラフ: 「型番A → 部品B-1 → サプライヤーX → 仕様変更通知Y」というように、エンティティとエンティティの関係を明示的に持つデータ構造(ノードとエッジ)
- ベクトル検索: 「自然文クエリに意味的に近い文章」を引く従来のやり方
- LLM: クエリ理解 + 結果統合 + 自然文回答
クエリが来たら、まずグラフ側で「関係をたどって関連エンティティを引き当てる」。そしてベクトル側で「自然文に近い説明文を補完する」。両方の結果をLLMが統合して答える——この二段構えが、製造業の「関係性が本体」の資料にはまります。
実際、ベクトル検索だけでは「答えられなかった質問」が、グラフのエッジをたどることで「答えられるようになる」。ここが現場で効いてくる一番の差です。技術的な詳細は割愛しますが、構成イメージはこんな感じです。
[ユーザー質問]
↓
[クエリ分解 / LLM]
↓
├─→ [Knowledge Graph検索] 関連エンティティと関係を取得
└─→ [Vector検索] 関連説明文を取得
↓
[コンテキスト統合 / LLM]
↓
[回答]
普通のRAGとの構造差は、本記事に載せた図解にもまとめています。
3ヶ月でやった実装ステップ — 設計が9割、実装が1割
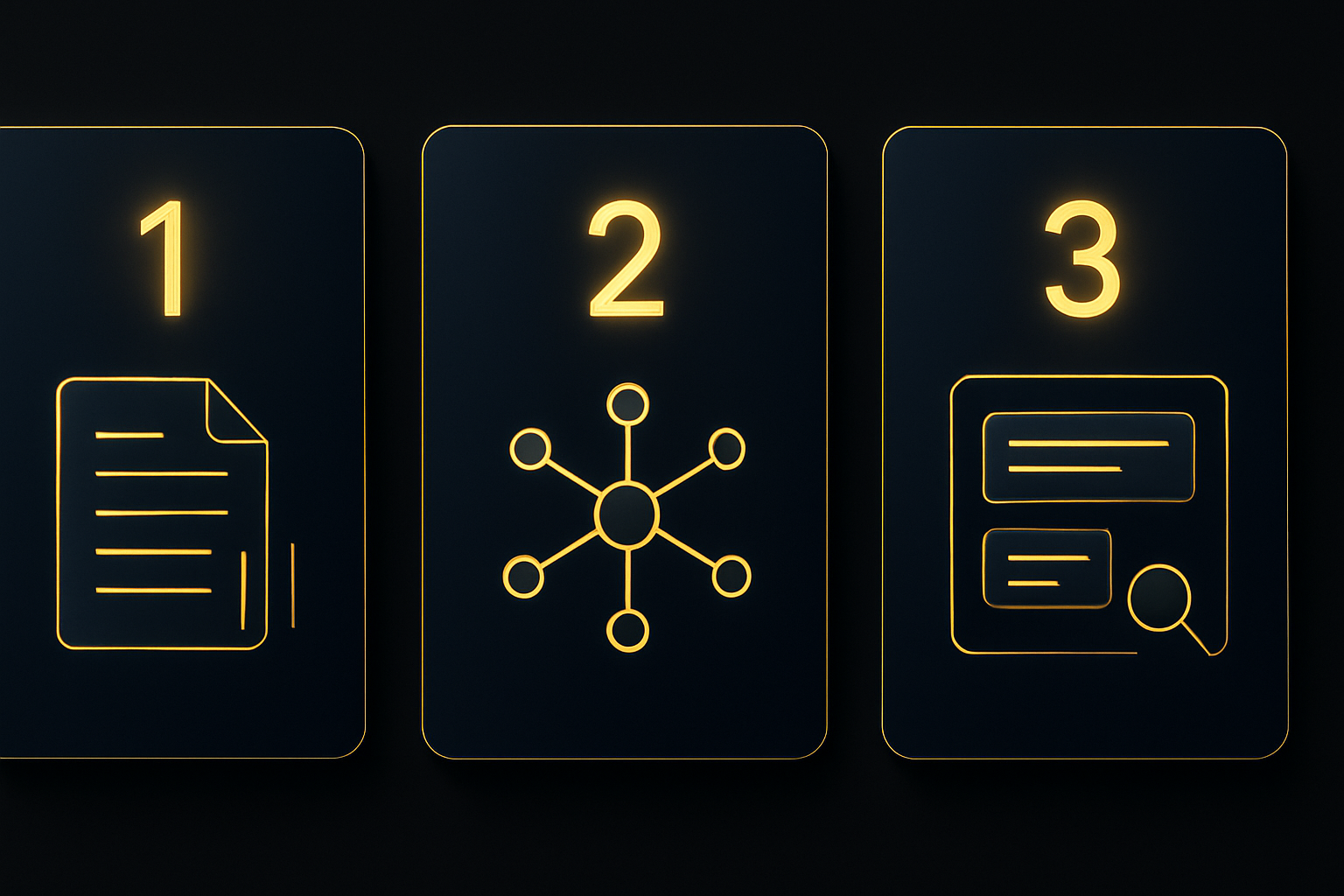
実装のステップを書くと、技術ブログっぽい体裁になります。が、強調したいのは「ステップ1の設計が全体の9割を占めた」という事実です。
実装ステップは、ざっくり3つ。
ステップ1: ナレッジグラフのスキーマ設計(≒ 9割の時間)
最初にやったのは、「何をノードにして、何をエッジにするか」を決めること。お客さんの図面・仕様書・部品表・改訂台帳を1ヶ月読み込んで、こういうスキーマに落としました(簡略化しています)。
- ノード: 製品 / 型番 / 部品 / 図面 / 仕様書 / 改訂 / サプライヤー / 規格
- エッジ:
consists_of(製品→部品)/documented_by(部品→図面)/revises(改訂→改訂)/supplied_by(部品→サプライヤー)/complies_with(部品→規格) など
このスキーマが甘いと、後でいくら実装しても引けないクエリが出てきます。ここはお客さんの現場担当(ベテラン設計者)と週1で議論しながら、3週間以上かけて固めました。
僕らがしくじったポイントを1つだけ書くと、最初「図面と仕様書を同じノード(Documentノード)にまとめた」ら、後で改訂のエッジが張れなくなって全部やり直しました。図面と仕様書は別物として扱うのが正解でした。
ステップ2: 抽出・構築パイプライン(≒ 1割の前半)
スキーマが決まったあとは、ひたすらデータを入れる作業です。
- 図面PDF → OCR(Azure Document IntelligenceとTesseractを併用)→ 表題欄から型番・図番・改訂を抽出 → 図面ノードとして登録
- 仕様書PDF → テキスト抽出 → LLM(Claude 3.5 Sonnet)でエンティティ抽出 → ノード・エッジとして登録
- 部品表CSV / 改訂台帳CSV → 構造化データなので素直に流し込む
- 同時に各ドキュメントの本文Chunkをベクトル化してベクトルDBに格納
ここは普通のパイプライン処理です。難しいのは「抽出の精度をどこまで詰めるか」だけ。
ステップ3: クエリ・回答層(≒ 1割の後半)
ユーザーの自然文クエリを、
- LLMに「これはグラフクエリ?ベクトルクエリ?両方?」と分類させる
- グラフ側はCypherクエリに変換、ベクトル側は通常の類似検索
- 結果を統合してLLMに渡し、自然文で回答させる
という流れで実装しました。ここはLangChainやLlamaIndexのGraphRAG実装を参考にしつつ、お客さんの語彙(型番の付け方とか、現場で使う略語とか)に合わせてカスタムしました。
「自社の図面・仕様書だと、どんなノードとエッジになるんだろう?」と気になった方へ。スキーマのたたき台づくりは、記事末尾の相談先から30分の壁打ちでお手伝いできます。手元の図面を1枚見せてもらえれば、設計の勘所はだいたい掴めます。
つまずきポイント3つ(OCR精度・グラフのスキーマ設計・更新サイクル)
「導入してみたい」と思った方のために、僕らが3ヶ月でハマった落とし穴を3つ書いておきます。
1. 図面のOCR精度が、最初の壁
古い図面はスキャンが斜めだったり、表題欄のフォントが手書きだったりします。Azure Document Intelligenceでも、初期は型番認識率が8割切ってました。
対策として、表題欄のテンプレートを事前学習させ、さらに「OCR結果が怪しい場合は人がレビューに回せるUI」を作りました。完全自動化は諦めて、人を組み込む設計にした方が現実的でした。
2. グラフのスキーマ設計は、実装より先にやる
これは前にも書きましたが、本当に大事なので2回書きます。スキーマ設計を後回しにして「とりあえずグラフDB立てて、入れながら考えよう」とやると、3週間後に全部やり直しになります。
最初の1ヶ月は、コードを書くよりお客さんと一緒に紙とホワイトボードで設計図を描く時間に使ってください。
3. 更新サイクルをグラフに組み込まないと、3ヶ月で陳腐化する
製造業の図面・仕様書は、生き物です。改訂が常に走っています。
僕らは最初、「初回データ移行で終わり」という設計にして、3ヶ月後に「もう古い情報しか返ってこない」と言われました。今は、
- 新しい図面・仕様書がアップロードされたら自動でパイプラインに流す
- 改訂イベントが発生したらグラフのエッジを自動更新する
という仕組みを後付けで組み込んでいます。最初から「更新フロー」をスキーマ設計に含めておくべきでした。
中小製造業のRAG導入を検討している経営者へ — 「最小のスタート」3つ
ここまで読んで「うちもやってみたい」と思った経営者の方に、最後に3つだけ提案させてください。
提案1: 最初の3ヶ月は"プロトタイプ"ではなく"設計"に使う
GraphRAG(に限らず、業務特化のRAG全般)は、設計フェーズの妥協が後で全部跳ね返ってきます。「まずプロトタイプを作って動かしてみよう」ではなく、「3ヶ月かけてスキーマと運用フローを固めて、動くものは4ヶ月目から出す」くらいの覚悟が要ります。
提案2: ターゲットを1領域に絞る
「全社の図面・仕様書を全部検索可能に」は地獄です。最初は「ある製品ラインの図面と部品表だけ」「ある工場の品質規格書だけ」など、エンティティの種類を絞ってください。MVPとして動かしてから、領域を広げる方が圧倒的に速いです。
提案3: ベンダーロックインを避ける構成にする
GraphRAGは特定のSaaSに依存させずに組めます。グラフDBはNeo4j or Memgraph、ベクトルはpgvector or Qdrant、LLMは適宜差し替え可能——というオープンな構成にしておくと、3年後にコスト見直しができます。最初から特定の生成AI製品にロックインする構成は、コスト面で後悔します。
まとめ
中小製造業のRAGは、普通のベクトル検索RAGでは詰みます。「関係性が情報の本体」「改訂履歴がエグい」「図面はChunkしても意味を持たない」——この3つの構造的特性のせいです。
解決策がGraphRAG。ナレッジグラフとベクトル検索の二段構えで、ようやく「型番→部品→図面→改訂履歴→仕様書」をつなげて引ける検索になります。
そして、これは技術選定の話というより、設計が9割、実装が1割の話です。最初の3ヶ月をスキーマ設計とお客さん業務理解に使えるかどうかで、出来上がるRAGの質が変わります。
僕らK.Platinumは、AI・RAG × 製造業 という領域で受託開発をやっています。「過去案件の図面・仕様書の検索」「品質規格の社内RAG化」「ベテラン技術者の暗黙知のグラフ化」あたりに困っている経営者の方は、お気軽にご相談ください。最初の30分は壁打ちでもOKです。
筆者プロフィール
沼田海斗 / 株式会社K.Platinum代表
高専卒 → トヨタ → スタートアップITコンサル → 24歳で起業 → 現在3期目・27歳。17人のITコンサル組織を率いる。AI・RAG × 製造業 / 受託開発 を主戦場としています。趣味はキックボクシング。
お問い合わせ: https://k-platinum.com